Credit Scoring Feature Selection Example
Feature Selection identifies the most informative variables for a predictive model. In credit scoring, the goal is typically to predict whether a borrower will default or not, which is represented by binary labels (e.g., 0 = no default, 1 = default).
This formulation selects a subset of features that maximizes correlation with the target variable (predictive power) while minimizing redundancy between features (to avoid overlapping information). The trade-off between these objectives is controlled by a parameter, encouraging solutions that balance relevance and diversity among the selected features.
import getpass
import os
import numpy as np
from dotenv import load_dotenv
from luna_quantum.algorithms import SCIP
from luna_usecases.credit_scoring_feature_selection import (
CreditScoringFeatureSelectionCollection,
CreditScoringFeatureSelectionData,
CreditScoringFeatureSelectionFormulation,
CreditScoringFeatureSelectionInstance,
)
load_dotenv()
if "LUNA_API_KEY" not in os.environ:
os.environ["LUNA_API_KEY"] = getpass.getpass("Enter your Luna API key: ")
Create Data
Define a credit scoring dataset with 6 applicants and 4 features (age, income, score, history). labels
design_matrix = np.array(
[
[25, 50000, 720, 2],
[35, 80000, 780, 4],
[45, 60000, 690, 1],
[30, 90000, 760, 2],
[50, 40000, 650, 0],
[28, 70000, 740, 4],
]
)
labels = [0, 0, 1, 0, 1, 0]
data = CreditScoringFeatureSelectionData.from_values(design_matrix=design_matrix, labels=labels, alpha=0.5)
print(data.to_string())
Plot Data
Visualize feature distributions across credit classes.
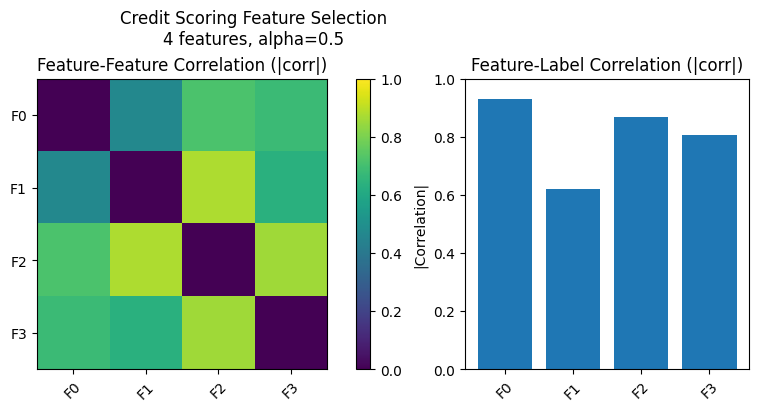
Create Formulation
Select the most predictive feature subset using a QUBO formulation.
Credit Scoring Feature Selection Formulation:
Features: 4
Samples: 6
Alpha: 0.5
Decision Variables:
x[i] in {0,1} for i = 0, ..., 3
x[i] = 1 if feature i is selected
Total: 4 binary variables
Objective:
maximize alpha * sum_i corr_label[i] * x[i]
- (1 - alpha) * sum_False corr_feat[i,j] * x[i] * x[j]
Constraints:
None (unconstrained)
Create Instance
Combine data and formulation into a solvable instance.
instance = CreditScoringFeatureSelectionInstance(data=data, formulation=formulation)
print(instance.to_string())
Data:Credit Scoring Feature Selection Data:
Samples: 6
Features: 4
Alpha: 0.5
Label balance: 0=4, 1=2
Formulation:Credit Scoring Feature Selection Formulation:
Features: 4
Samples: 6
Alpha: 0.5
Decision Variables:
x[i] in {0,1} for i = 0, ..., 3
x[i] = 1 if feature i is selected
Total: 4 binary variables
Objective:
maximize alpha * sum_i corr_label[i] * x[i]
- (1 - alpha) * sum_False corr_feat[i,j] * x[i] * x[j]
Constraints:
None (unconstrained)
Formulate Model
Translate the instance into a mathematical optimization model.
Solve and Interpret
Solve the model with SCIP and interpret the raw result into a use-case-specific solution.
scip = SCIP()
job = scip.run(model)
sol = job.result()
uc_solution = instance.interpret(sol)
print(uc_solution.to_string())
/Users/maximilianjanetschek/PycharmProjects/luna-usecases/.venv/lib/python3.13/site-packages/rich/live.py:260:
UserWarning: install "ipywidgets" for Jupyter support
warnings.warn('install "ipywidgets" for Jupyter support')
2026-05-29 11:33:30 INFO Sleeping for 5.0 seconds. Waiting and checking a function in a loop.
2026-05-29 11:33:37 INFO Sleeping for 10.0 seconds. Waiting and checking a function in a loop.
2026-05-29 11:33:48 INFO Sleeping for 15.0 seconds. Waiting and checking a function in a loop.
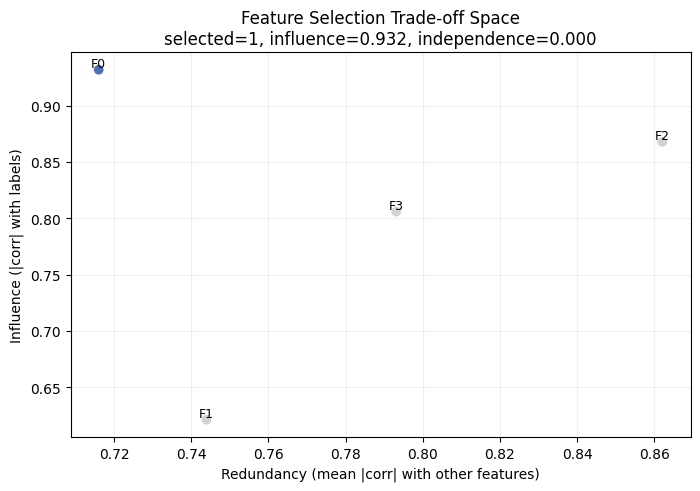
Credit Scoring Feature Selection Solution:
Selected features: [0]
Influence score: 0.9318485437788233
Independence score: 0.0
Valid: True
Plot Solution
Visualize the optimal solution.
<Axes: title={'center': 'Feature Selection Trade-off Space\nselected=1, influence=0.932, independence=0.000'}, xlabel='Redundancy (mean |corr| with other features)', ylabel='Influence (|corr| with labels)'>
Collections
Generate a benchmark collection of random instances for batch processing.
collection = CreditScoringFeatureSelectionCollection.from_random(
min_size=4, max_size=8, num_instances=1, n_samples=20, alpha=0.5, seed=42
)
model = collection.instances[0].formulate()
print(model)
Model: credit_scoring_feature_selection<credit_scoring_feature_selection>
Maximize
-0.05525998531698857 * x_0 * x_1 - 0.06282849724852296 * x_0 * x_2
- 0.14383103386753227 * x_0 * x_3 - 0.41721170409928643 * x_1 * x_2
- 0.2520532722752783 * x_1 * x_3 - 0.1766337591341169 * x_2 * x_3
+ 0.36634960890022616 * x_0 + 0.10244618603962699 * x_1
+ 0.1096902833547969 * x_2 + 0.0357968007481356 * x_3
Binary
x_0 x_1 x_2 x_3